|
Logo
|
Title
|
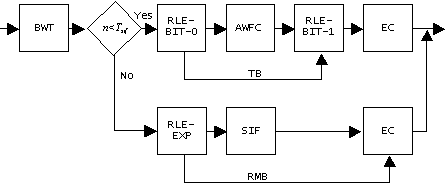
Description
|
|
|
Grundlagen des Burrows-Wheeler-Kompressionsalgorithm us
|
A German article from 2003 by Jürgen Abel about the principles of the Burrows-Wheeler Compression Algorithm, written for the journal "Informatik - Forschung und Entwicklung", Springer-Verlag Heidelberg, Germany, Association for Informatics (Gesellschaft für Informatik eV.). The article describes a BWCA implementation with a RLE and WFC stage.
The BWCA approach PIK03 achieves a compression rate of 2.25 bps for the Calgary Corpus.
|
|
|
Verlustlose Datenkompression auf Grundlage der Burrows-Wheeler-Transformation
|
Another German article from 2003 by Jürgen Abel about the basics of the Burrows-Wheeler Compression Algorithm, written for the journal "PIK - Praxis der Informationsverarbeitung und Kommunikation", Saur Verlag, Germany, Association for Informatics (Gesellschaft für Informatik eV.). The paper describes a simple but fast BWCA implementaion PIK03 with a MTF, RLE0 and EC stage, which has the same compression speed as GZIP and BZIP2.
The BWCA approach PIK03 achieves a compression rate of 2.35 bps for the Calgary Corpus.
|
|
|
Improvements to the Burrows-Wheeler Compression Algorithm: After BWT Stages
|
A BWCA paper from 2003 by Jürgen Abel, which gives a short introduction into the BWCA field and proposes several improvements for the WFC stage and the IF stage and introduces a new RLE scheme for bypassing the run length information around the WFC stage. This paper is the basis of the program ABC.
This BWCA approach achieves a compression rate of 2.24 bps for the Calgary Corpus.
|
|
|
Universal Text Preprocessing for Data Compression
|
This paper from 2003 by Jürgen Abel and Bill Teahan presents several preprocessing algorithms for textual data, which work with BWT, PPM and LZ based compression schemes. The algorithms need no external dictionary and are language independent. The average compression gain is in the range of 3 to 5 percent for the text files of the Calgary Corpus and between 2 to 9 percent for the text files of the large Canterbury Corpus.
|
|
|
Record Preprocessing for Data Compression
|
Another preprocessing paper from 2003 by Jürgen Abel. The paper reveals a preprocessing algorithm which exploits the structure of record based files. The compression rate of these files can be enhanced if the file is byte-wise transposed before compression and after decompression by the record length. The approach is able to detect files with such a structure and to determine the corresponding record length.
|
|
|
Post BWT stages of the Burrows-Wheeler compression algorithm
|
A paper from 2010 by Jürgen Abel describing several post BWT stages including a new context based approach. The article includes comparisons of compression rates and compression rtimes of the different algorithms. Software: Practice and Experience, 40(9), 751-777, 2010.
|
|
|
DNA sequence compression using the Burrows-Wheeler Transform
|
Don Adjeroh, Yong Zhang, Amar Mukherjee, Matt Powell and Tim Bell present in 2002 a proposal for compressing DNA sequences by using an off-line dictionary oriented approache in combination with a BWCA.
|
|
|
On Compressibility of Protein Sequences
|
Don Adjeroh and Fei Nan wrote a paper about the compression of protein sequences at the DCC 2006. The algorithm used is based on a BWT with a dictionary stage following.
|
|
|
Text Compression with the Burrows-Wheeler Transform
|
James Allen gives a introduction of the BWT and presents a simple BWCA implementation with source code in C on his internet site from 2002. He uses two coding stages I haven't seen anywhere else in the BWCA field: Zero Running (ZR) after the MTF stage and Elias's gamma coding as the EC stage.
|
|
|
Lexical Permutation Sorting Algorithm
|
This article by Ziya Arnavut and Spyros Magliveras from 1996 describes a "Lexical Permutation Sorting Algorithm" (LPSA), which is a generalization of the Burrows-Wheeler Compression Algorithm (BWCA).
|
|
|
Block Sorting and Compression
|
This article by Ziya Arnavut and Spyros Magliveras from 1997 describes a "Lexical Permutation Sorting Algorithm" (LPSA), which is a generalization of the Burrows-Wheeler Compression Algorithm (BWCA), and a new post-BWT stage, called Inversion Frequencies (IF).
|
|
|
Move-to-Front and Inversion Coding
|
This conference proceeding paper from Ziya Arnavut at DCC 2000 compares the MTF stage with the IF stage. The IF stage, called inversion coding (ranking) technique, yields better compression gain than the recency ranking (MTF coder) for almost all the test data files.
|
|
|
Investigation of Block-Sorting of Multiset Permutations
|
Ziya and Meral Arnavut investigate in this 2004 article special cases of permutations, called multiset permutations, together with a transform different to the BWT, called Linear Ordering Transformation (LOT). LOT sorts rows of a cyclic rotated matrix with respect to the first element of each row.
|
|
|
Inversion Coder
|
A paper from 2004 by Ziya Arnavut presents and compares different inversion ranking schemes (IF) with recency ranking schemes (MTF). For large files, image and DNA files, IF achieves better compression rate than MTF schemes.
|
|
|
LIPT: A reversible lossless text transform to improve compression performance
|
In this paper from 2001 by Fauzia Awan, Nan Zhang, Nitin Motgi, Raja Iqbal and Amar Mukherjee a text pre-processing algorithm is described for PPM and BWCA, which leads to a better compression rate. The gain for BWCA is around 5% on the Calgary Corpus. The algorithm replaces words by sequneces of "*" and letters.
By using an extern dictionary it is dependent on a specific language.
|
|
|
A new text preprocessing algorithm for bzip2 and PPM
|
This is the same article from 2001 than "LIPT: A reversible lossless text transform to improve compression performance" by Fauzia Awan, Nan Zhang, Nitin Motgi, Raja Iqbal and Amar Mukherjee about text pre-processing for PPM and BWCA.
|
|
|
Selective Application of Burrows-wheeler Transformation for Enhancement of JPEG Entropy Coding
|
Hyun-Kee Baik, Dong Ha, Hyun-Gyoo Yook, Sung-Chul Shin and Myong-Soon Park describe in their paper from 1999 a variant of a BWCA in order to improve jpg-image compression.
|
|
|
A New Method to Improve the Performance of JPEG Entropy Coding Using Burrows-Wheeler Transformation
|
Another paper by Hyun-Kee Baik, Hyun-Gyoo Yook, Sung-Chul Shin, Myong-Soon Park and Dong Sam Ha from 1999 about using BWCA for jpg-image compression.
|
|
|
Universal Data Compression Based on the Burrows-Wheeler Transformation: Theory and Practice
|
Bernhard Balkenhol and Stefan Kurtz describe in their article from 1998 a BWCA which uses a BWT, MTF, RLE0 and EC stage.
This BWCA approach achieves a compression rate of 2.32 bps for the Calgary Corpus.
|
|
|
Modifications of the Burrows and Wheeler Data Compression Algorithm
|
This paper of Bernhard Balkenhol, Stefan Kurtz and Yuri Shtarkov from 1999 describes a modification of the MTF algorithm, which moves the next symbol to the second place in the list instead of the first place, except the old position of the new symbol was 0 or 1, then it is moved to the first place.
This BWCA approach achieves a compression rate of 2.30 bps for the Calgary Corpus.
|
|
|
One attempt of a compression algorithm using the BWT
|
Another important paper of Bernhard Balkenhol and Yuri Shtarkov from 1999 with focus on improvements of the Burrows-Wheeler Compression Algorithm (BWCA).
It includes some interesting aspects for the RLE field too. An important property of the output of the BWT is the presents of many runs, which results in overestimating the probability of symbols outside the run. This problem is called "Pressure of Runs" and can be decreased by RLE. Besides that, a modification of the MTF algorithm is described which moves the next symbol to the second place in the list instead of the first place, except the old position of the new symbol was 0 or 1. If the old position of the new symbol was 1 it is moved to the first place only if the last output number was different from 0.
This paper is my favourite paper from Bernhard.
This BWCA approach achieves a compression rate of 2.26 bps for the Calgary Corpus.
|
|
|
Tree Source Identification with the Burrows Wheeler Transform
|
Dror Baron and Yoram Bresler study in their article from 2000 the identification of a tree source model from a given sequence by using the BWT as a sorting transformation for states in the tree.
|
|
|
A locally adaptive data compression scheme
|
The original MTF paper of Jon Bentley, Daniel Sleator, Robert Tarjan and Victor Wei from 1986. The paper descibes a word based MTF scheme as a data compression scheme, that exploits locality of reference. It is based on a simple heuristic for self-organizing sequential search.
|
|
|
Distance Coding newsgroup message
|
The famous newsgroup posting from 2000 by Edgar Binder, where he describes the DC algorithm by an example together with 3 important properties of the DC output sequence.
|
|
|
Inverting the Burrows-Wheeler Transform
|
Richard Bird and Shin-Cheng Mu describe in their brief article from 2001 the inverse transformation of the BWT.
|
|
|
A Block-Sorting Lossless Data Compression Algorithm
|
Michael Burrows and David Wheeler introduce the Burrows-Wheeler Transform (BWT) and the Burrows-Wheeler Compression Algorithm (BWCA) in a research report from 1994 at the Digital Systems Research Center. The paper explains the transformation and why the output sequence compresses well. Some variants of the algorithm, such as a modified MTF, are named too.
This paper is a "must" for everyone interested in BWCAs.
This BWCA approach achieves a compression rate of 2.43 bps for the Calgary Corpus.
|
|
|
On variants of block-sorting compression using context from both the left and right
|
Michael Burrows and Li Zhang describe a variation of BWT, which sorts contexts from left and right. The problem is, that the output of the new transfrom is not unambiguously, meaning that different input strings are transformed to the same output string. In order to unambiguously decode the output, one has to add log n-bits to the output.
|
|
|
BWT, a transformation algorithm
|
A brief article by Anturo San Emeterio Campos from 1999, describing the basics of the BWT.
|
|
|
Higher Compression from the Burrows-Wheeler Transform by Modified Sorting
|
Brenton Chapin and Stephen Tate show in their article from 1998, that the sorting order of the alphabet has a significant impact on the compression rate of a BWCA. They present a heuristic manuel alphabet permutation and a calculated alphabet permutation. The prsented calculated alphabet permutation does not improve the compression rate in all cases. For text files their heuristic manuel alphabet permutation achieves better results.
|
|
|
Switching Between Two On-Line List Update Algorithms for Higher Compression of Burrows-Wheeler Transformed Data
|
In his article from 2000 Brenton Chapin describes a switching scheme between two list update algorithms for a BWCA, a MTF scheme and a so called "Best x of 2x - 1" algorithm.
This BWCA approach achieves a compression rate of 2.33 bps for the Calgary Corpus.
|
|
|
Higher Compression from the Burrows-Wheeler Transform with new Algorithms for the List Update Problem
|
The doctoral thesis of Brenton Chapin describes not only different LUAs but also some preprocessing schemes like alphabet reordering and variations of the BWT (Gray code sort) in order to achieve better compression rates.
|
|
|
The Burrows-Wheeler block sorting algorithm (long)
|
A short introduction into the BWT can be found at the comp.compression FAQ from 1999. The internet site has a little example and describes briefly the BWCA.
|
|
|
An analysis of the second step algorithms in the Burrows-Wheeler compression algorithm
|
A quite similar publication from 2000 to the article "Second step algorithms in the Burrows-Wheeler compression algorithm" from Sebastian Deorowicz, describing his Weighted Frequency Count Algorithm.
This BWCA approach achieves a compression rate of 2.25 bps for the Calgary Corpus.
|
|
|
Improvements to Burrows-Wheeler Compression Algorithm
|
Sebastian Deorowicz describes in his article from 2000 a BWCA, based on a modified MTF and RLE0 stage. He also uses an adapted EC stage.
This BWCA approach achieves a compression rate of 2.27 bps for the Calgary Corpus.
|
|
|
Second step algorithms in the Burrows-Wheeler compression algorithm
|
This publication of Sebastian Deorowicz in "Software-Practice and Experience" from 2002 give a quite complete overview of the post BWT stages used within the Burrows-Wheeler Compression Algorithm. Besides his own Weighted Frequency Count Algorithm and other post BWT stages, Sebastian describes briefly but clearly variantions of the Move To Front scheme, the Inversion Frequencies algorithm and the Distance Coding algorithm with the 3 properties of the newsgroup posting. This is one of my favourite BWCA papers.
This BWCA approach achieves a compression rate of 2.25 bps for the Calgary Corpus.
|
|
|
Universal lossless source coding with the Burrows Wheeler transform
|
The work from 1999 of Michelle Effros, Karthik Visweswariah, Sanjeev Kulkarni, Sergio Verdú gives a theoretical evaluation of BWT-based coding. It prooves that BWT-based lossless source codes achieve universal lossless coding performance that converges to the optimal coding performance more quickly than the rate of convergence observed in LZ-style codes.
|
|
|
Textkomprimierung - Multimedia-Seminar
|
Stefan Fabrewitz describes in his German seminar paper from 2000 several compression methods for text compression. He also has a brief chapter about the BWT.
|
|
|
Experiments with a Block Sorting Text Compression Algorithm
|
In his article form 1995 Peter Fenwick desribes several variations of BWCAs, One variation is a modified MTF scheme, which does not allways move the current symbol to the very front of the list but a little bit behind (index greater than 0). These appraoches achieved normaly a reduction in compression performance. He also describes some sorting improvements.
This BWCA approach achieves a compression rate of 2.43 bps for the Calgary Corpus.
|
|
|
Improvements to the Block Sorting Text Compression Algorithm
|
Peter Fenwick introdues 1995 some BWCA improvements and variations like sort improvements, LZ77 preprocessing, a delta model and the direct coding of the BWT output.
This BWCA approach achieves a compression rate of 2.36 bps for the Calgary Corpus.
|
|
|
Block Sorting Text Compression - Final Report
|
This technical paper is one of Peters most important BWCA papers published in 1996. Peter describes the basic transformation by an example and several improvements of the basic algorithm, like hierarchical coding models, structured coding models and Wheelers Run Length Encoding for zeros (RLE0). He also gives some sort and MTF improvements and a interpretation of the BWT output sequence.
This is a "must", if you are interested in the BWCA field.
This BWCA approach achieves a compression rate of 2.34 bps for the Calgary Corpus.
|
|
|
Block Sorting Text Compression / Proceedings of the 19th Australian Computer Science Conference 1996
|
This paper is similar to Peters "Block Sorting Text Compression - Final Report" and shows about the same several variants and improvements to BWCAs.
This BWCA approach achieves a compression rate of 2.34 bps for the Calgary Corpus.
|
|
|
Burrows Wheeler - Alternatives to Move to Front
|
The paper from 2003 by Peter Fenwick, Mark Titchener and Michelle Lorenz describes a cached MTF modeling scheme with a foreground (more frequent symbols) and background (less frequent symbols) model. It also introduces the so called T-entropy as a measurement for entropies after each BWCA stage.
|
|
|
Burrows-Wheeler Compression with Variable Length Integer Codes
|
Peter describes in his paper from 2002 an alternative to arithmetic or Huffman coding at the last stage of a BWCA by using variable length integer codes (Elias Gamma and Fraenkel-Klein Fibonacci codes). Furthermore a sticky MTF stage is revealed, which move a accessed symbol back to 40% where it come from except if the symbol is accessed twice at once.
|
|
|
An experimental study of an opportunistic index
|
In the article from 2001 Paolo Ferragina and Giovanni Manzini combine the BWCA with with the suffix array data structure in order to support data indexing.
|
|
|
Lossless, Reversible Transformations that Improve Text Compression Ratios
|
In their paper form 2000 Robert Franceschini, Holger Kruse, Nan Zhang, Raja Iqbal and Amar Mukherjee desribe 3 text preprocessing techniques for BWCAs and PPM: LPT, RLPT and SCLPT. The achieve a compression gain of 7.1% over BZIP. The disadvantages of their method are, that they are language dependent and that they need an extern dictionary.
|
|
|
Compression, part 3: Burrows-Wheeler transform
|
A short introduction into the BWT with some examples is presented by Ole Friis on his internet site from 2001.
|
|
|
Burrows-Wheeler Transform in image compression
|
Markus Gärtner and David Havelin present on their internet site from 2000 a project for compression of images by using a transformation of the image, like DCT or DWT, before using the BWCA. They also plan to adept the BWT in order to process 2-dimensional data.
|
|
|
A space-economic suffix tree construction algorithm (Powerpoint Slides)
|
This powerpoint slide from 1997 by Robert Giegerich and Stefan Kurtz explains the suffix tree construction algorithm of McCreight from 1976.
|
|
|
Efficient Implementation of Lazy Suffix Trees
|
Robert Giegerich, Stefan Kurtz and Jens Stoye present 1999 time and space efficient suffix sorting algorithms.
|
|
|
Text Preprocessing for Burrows-Wheeler Block-Sorting Compression
|
This paper from 1999 by Szymon Grabowski is an interesting text preprocessing paper for BWCAs. It describes capital conversion, space stuffing, phrase substitution, alphabet reordering and EOL coding. A drawback is the dependence on the English language.
|
|
|
Parsing Strategies for BWT Compression
|
Yugo Isal and Alistair Moffat descrribe in their paper from 2001 several parsing preprocessing schemes for BWCAs. They use word and n-gram techniques with implicit and explicit dictionaries. In all cases the dictionary information is coded and transmitted too, so their techniques remain language independent.
|
|
|
Enhanced Word-Based Block-Sorting Text Compression
|
This paper from 2002 by Yugo Isal, Alistair Moffat and Alwin Ngai explains word based preprocessing schemes and a ranking scheme for the GST, called DSEG, which uses search trees to calculate proper ranking values.
|
|
|
An Efficient Method for Construction of Suffix Arrays
|
This paper from 1999 about suffix sorting is an important BWT paper by Hideo Itoh and Hozumi Tanaka. It descibes the two-stage suffix sort, which is a very fast sorting algorithm for suffices. It can be used in order to calculate the BWT very efficiently.
|
|
|
Simple Linear Work Suffix Array Construction
|
A very interesting paper from Juha Kärkkäinen and Peter Sanders from 2003 at the Max-Planck-Institut für Informatik about a simple suffix sorting in linear time. It sorts suffices beginning at positions (i mod 3 <> 0) recursivly and the remaining suffices and merges them at the end.
|
|
|
Improving Suffix-Array Construction Algorithms with Applications
|
One of my favourite BWT sorting articles from 2001 by Tsai-Hsing Kao as a Masters thesis. He describes an improved version of the two-stage suffix sort from Hideo Itoh and Hozumi Tanaka by going through the sorting array both from left to right and from right to left. The thesis also explains related algorithms like Sadakanes sorting.
|
|
|
Preprocessing Text to Improve Compression Ratios
|
This paper from 1997 by Holger Kruse and Amar Mukherjee describes a text preprocessing techniques for BWCAs, called star encoding. The presented method is language dependent and need an extern dictionary.
|
|
|
Improving Text Compression Ratios with the Burrows-Wheeler Transform
|
Holger Kruse and Amar Mukherjee describe in their paper from 1999 three text preprocessing schemes: alphabet reordering, bi-gram encoding and dictionary encoding. The presented method is language dependent and need an extern dictionary.
|
|
|
Reducing the Space Requirement of Suffix Trees
|
Stefan Kurtz introduces in his article from 1998 a suffix tree algorithm, which needs only about half as much space (10 - 20 bytes per input symbol) than previous algorithms.
|
|
|
Space Efficient Linear Time Computation of the Burrows and Wheeler-Transformation
|
Stefan Kurtz and Bernhard Balkenhol present in their paper from 1999 a suffix tree algorithm for BWT, which needs few space and is linear in time.
|
|
|
Extended application of suffix trees to data compression
|
A method for constructing a suffix tree in linear time within a sliding window is presented by Jesper Larsson in 1998. It has some relations to LZ, PPM* and ACB by George Buynovksy.
|
|
|
The Context Trees of Block Sorting Compression
|
Jesper Larsson describes in his paper from 1998 a method, which calculates a suffix tree, prunes the tree, encodes the tree and uses the transmitted tree information for a GST stage inside the BWCA.
This BWCA approach achieves a compression rate of 2.65 bps for the Calgary Corpus.
|
|
|
Notes On Suffix Sorting
|
Jesper Larsson reveals in his paper from 1998 some improvements over Sadakanes suffix sort algorithm, which can be used to calculate the BWT. He also gives some theoretical time complexity estimates of the algorithm.
|
|
|
Faster Suffix Sorting
|
Jesper Larsson and Kunihiko Sadakane describe a fast algorithm for sorting suffix array in their paper from 1999, which can be used to calculate the BWT. This is one of my favourite articles about suffix sorting for BWT.
|
|
|
Structures of String Matching and Data Compression
|
The doctoral thesis of Jesper Larsson from 1999 about suffix trees, suffix arrays, context trees, BWT and their relations. Important fpr the BWT area is the chapter about a fast construction of a suffix array, where Jesper Larsson reveils several algorithm refinements together with examples of source code. This work is highly recomended for calculation of the BWT.
|
|
|
Datenkompression (German Script)
|
Maciej Liskiewicz and Henning Fernau describe in their German paper from 1999 several compression techniques both for lossless and for lossy compression. The paper contains a very brief chapter about BWT.
|
|
|
A Run Length Encoding Scheme For Block Sort Transformed Data
|
Michael Maniscalco describes in 2000 a RLE algorithm for usage within the Burrows-Wheeler Compression Allgorithm, which is based on a fixed length threshold run and a symbol run which is about half as long as the original run.
|
|
|
A Second Modified Run Length Encoding Scheme For Block Sort Transformed Data
|
This RLE algorithm from 2001 by Michael Maniscalco is based on a variable length threshold run, which defines the length of the binary representation of the threshold run and a mantissa part, which is stored in a separate data buffer.
|
|
|
An Analysis of the Burrows-Wheeler Transform
|
A theoretical paper from 1999 by Giovanni Manzini, which analyses the properties of a BWCA with a MTF stage and a BWCA with a MTF and RLE0 stage.
|
|
|
The Burrows-Wheeler Transform: Theory and Practice
|
Another paper from 1999 by Giovanni Manzini, which analyses the BWCA and several variations like some implementations of Schindler and Sadakane.
|
|
|
Engineering a Lightweight Suffix Array Construction Algorithm
|
Giovanni Manzini and Paolo Ferragina introduce in their paper from 2002 an improved suffix array construction algorithm called Deep-Shallow Suffix Sorting and based on the Copy algorithm from Seward. The algorithm is able to calculate the BWT very fast.
|
|
|
Algorithms for Text and Image Compression
|
This paper from 1999 by Amar Mukherjee, Holger Kruse and Kunal Mukherjee describe algorithms for text and for image compression. The text compression algorithm is a BWCA with text preprocessing based on the Star (*) Encoding technique. The presented method is language dependent and need an extern dictionary.
|
|
|
Data Compression with the Burrows-Wheeler Transform
|
Mark explain in his Dr. Dobbs Journal article the basics of the BWT by some examples and presents a reference implementation of a BWCA. He also offers free source code for his BWCA.
This article his high recommendable for BWT beginners.
|
|
|
Protein is incompressible
|
The paper which introduced the 4 protein files by Craig Nevill-Manning and Ian Witten from the DCC 1999. They state that protein files are not very high compressable with PPM like algorithms and introduce a special protein compression program called CP.
Further investigation will have to find out, how much possibilities have BWCAs in the field of protein compression.
|
|
|
Comparison among Suffix Array Construction Algorithms
|
Kunihiko Sadakane compares different algorithms for constructing suffix arrays and introduces his new fast algorithm, which is effective if the length of repeated strings inside the text is large.
This paper from 1997 is a basic paper about calculating the BWT by suffix sorting.
|
|
|
Improvements of Speed and Performance of Data Compression Based on Dictionary and Context Similarity
|
The masters thesis of Kunihiko Sadakane from 1997 introduces the new compression algorithm Recency Rank Code with Context (RRC), which is related to context similarity schemes and BWCAs.
RRC achieves a compression rate of 2.48 bps for the Calgary Corpus.
|
|
|
Text Compression using Recency Rank with Context and Relation to Context Sorting, Block Sorting and PPM*
|
Kunihiko Sadakane describes in his paper from 1997, which is similar to his masters thesis, the compression algorithm RRC, which is related to blocksorting and context similarity schemes.
|
|
|
A Fast Algorithm for Making Suffix Arrays and for Burrows-Wheeler Transformation
|
This article by Kunihiko Sadakane from 1998 is very similar to his paper "Comparison among Suffix Array Construction Algorithms", and compares different algorithms for constructing suffix arrays.
It explains his fast algorithm for constructing suffix arrays.
|
|
|
On Optimality of Variants of the Block Sorting Compression
|
Kunihiko Sadakane proposes in this overview from 1998 two online algorithms based on blocksorting. In order to use the first algorithm, one has to know the order of the source, the second algorithm divides the input into pieces with same contexts and codes the pieces with seperated models.
|
|
|
A Modified Burrows-Wheeler Transformation for Case-insensitive Search with Application to Suffix Array Compression
|
This paper from 1999 by Kunihiko Sadakane introduces a BWT variant in order to support case-insensitive searches inside the text.
|
|
|
Unifying Text Search And Compression -Suffix Sorting, Block Sorting and Suffix Arrays
|
The doctoral thesis of Kunihiko Sadakane from 2000 proposes a unified method for improving efficiency of search and compression for huge text data. Besides many other aspects this paper includes the best and most extensive explanation of his famous suffix sorting algorithm.
Therefore I highly recommend this paper for informations about the fast algorithm of Sadakane for constructing suffix arrays.
|
|
|
Constructing Suffix Arrays of Large Texts
|
Kunihiko Sadakane and Hiroshi Imai describe in their brief paper from 1998 the algorithm of Sadakane for constructing suffix arrays.
|
|
|
A Fast Block-sorting Algorithm for lossless Data Compression
|
Michael Schindler proposes in his article from 1996 a variant of the BWT. The execution speed of his approach does not depend on the used blocksize.
|
|
|
Two New Families of List Update Algorithms
|
Frank Schulz presents in his paper from 1998 two list update algorithm families for the online accessing problem: Sort-By-Rank and Sort-By-Delay.
|
|
|
On the performance of BWT sorting algorithms
|
Julian Seward proposes in his paper from 2000 several very fast BWT algorithm, called COPY and CACHE, which are used in his fast BWCA implementation BZIP2.
This article is very recommendable for fast calculation of the BWT by suffix arrays.
|
|
|
Space-time tradeoffs in the Inverse B-W Transform
|
Several fast variants of calculating the inverse BWT are discussed in the article from 2001 by Julian Seward.
This article is very recommendable for inverse BWT calculation.
|
|
|
Packen wie noch nie
|
A German article from the ct magazine 2000 about a basic BWCA implementation by Michael Tamm.
|
|
|
The Entropy of English using PPM-Based Models
|
William Teahan and John Cleary descibe in their paper from 1996 the entropy of English text. For BWCAs this paper is interesting too, since it proposes bigram based text preprocessing, which can be used in the BWCA field too in order to improve the compression ratio.
|
|
|
Models of English Text
|
This article from 1997 by William Teahan and John Cleary descibe models of English text. The word based model can be used as a text preprocessing approach in the BWCA field in order to improve the compression ratio.
|
|
|
Modelling English text
|
In his doctoral thesis Bill describes properties of the English language and adaptive models of the English language for PPM based compression. The PPM* algorithm is described too.
For the BWCA field, the word based model can be used as a text preprocessing approach in order to improve the compression ratio.
|
|
|
Switching Between Two Universal Source Coding Algorithms
|
Paul Volf and Frans Willems present in their paper the basics of the switching method, which switches between two sequential compression algorithms in order to get a better compression rate than the rate of the algorithms seperatly.
Three algorithms are proposed, the switching algorithm, which stores all states, the Snake algorithm, which stores two stages, and the reduced complexity algorithm, a compromise which stores a fixed amount of stages.
The switching method can be applied in many cases, for example with PPM variants but also for some GST stages like MTF and WFC within BWCAs.
This switching approach achieves a compression rate of 2.14 bps for the Calgary Corpus.
|
|
|
The Switching Method: Elaborations
|
Paul Volf and Frans Willems extend the switching method by combining CTW with PPM variations in 1998.
This switching approach achieves a compression rate of 2.12 bps for the Calgary Corpus.
|
|
|
An implementation of block coding
|
This paper from 1995 by David Wheeler is a describtion of the program BRED, a BWCA implemenation of David Wheeler using Huffman coding as the EC stage.
A primed BWCA approach of BRED achieves a compression rate of 2.29 bps for the Calgary Corpus.
|
|
|
Upgrading bred with multiple tables
|
In his paper from 1997 David Wheeler describes improvents to his program BRED by using multiple tables for adaption to changing statistics.
This BWCA approach of BRED achieves a compression rate of 2.36 bps for the Calgary Corpus.
|
|
|
Can we do without ranks in Burrows Wheeler transform compression?
|
Anthony Ian Wirth and Alistair Moffat discuss in 2001 direct symbol encoding instead of ranks from the GST stage. They use a hierarchical model similar to the one from Balkenhol and Shtarkov.
This BWCA approach of BRED achieves a compression rate of 2.312 bps for the Calgary Corpus.
|
|
|
Symbol-driven compression of Burrows Wheeler transformed text
|
Anthony Ian Wirth wrote a masters thesis in 2001 about direct symbol encoding after the BWT stage. He describes a model for encoding similar to PPM.
This BWCA approach of BRED achieves a compression rate of 2.312 bps for the Calgary Corpus.
|
|
|
An Efficient Method For Compressing Test Data
|
This paper of Takahiro Yamaguchi, Marco Tilgner, Masahiro Ishida and Dong Ha from 1997 proposes a method for compressing test data by using the BWT and a RLE stage.
|
|
|
Approximate Pattern Matching Over the Burrows-Wheeler Transformed Text
|
Nan Zhang, Amar Mukherjee, Don Adjeroh and Tim Bell discuss approximate pattern matching on the output of the BWT stage in their paper from 2003.
|
|
Logo
|
Name
|
Description
|
|
|
Jürgen Abel
|
Jürgen Abel is the author of this site and of the compression program ABC. His research interests are data compression, data encryption, information retrievel and 3-D graphics.
|
|
|
Don Adjeroh
|
Donald Adjeroh works in the Department of Computer Science at the University of Canterbury, New Zealand. He is a member of the Digital Lectures Research Group.
|
|
|
Imran Akthar
|
Imran Akthar is an engineeering graduate from the Kuvempu University, India. He is interested in image processing and embedded systems and implemented a BWT encoder and decoder in MATLAB.
|
|
|
James Allen
|
James Allen is a computer programmer, interested in software or algorithm design. He helds 28 U.S. patents, 12 of them in the field of lossless coding.
|
|
|
Meral Arnavut
|
Meral Arnavut is an assistant orofessor at the Department of Mathematical Sciences at the State University of New York, Fredonia, United States of America. Her research interest is in Commutative Algebra, Ring Theory, Number Theory, Combinatorics and Data Compression.
|
|
|
Ziya Arnavut
|
Ziya Arnavut is a associate professor at the State University of New York, Fredonia, United States of America. He published several papers about data compression, particularly lossless image compression. He developed the Inversion Coder, which compresses very well DNA, image, audio and other signal-based data, in addition to large text files. His research interests are in data compression, image processing, multimedia, communications and combinatorial algorithms.
|
|
|
Fauzia Awan
|
Fauzia Awan made his Masters thesis about Lossless Reversible Text Transforms in 2001 at the University of Central Florida, United States of America.
|
|
|
Hyun-Kee Baik
|
Hyun-Kee Baik is a doctoral student at the Korea University, Korea.
|
|
|
Bernhard Balkenhol
|
Bernhard studied mathematics at the University of Bielefeld and works for the mediaWays GmbH in Germany. He is interested in information theory, data compression and encryption and has published several compression articles, which are available on his internet site.
|
|
|
Dror Baron
|
Dror is teaching an introductory class on image and video processing at the University of Illinois, United States of America.
|
|
|
Tim Bell
|
Timothy Bell works at the University of Canterbury, New Zealand, and is "father" of the Canterbury Corpus. His research interests include compression, computer science for children, and music.
|
|
|
Jon Bentley
|
Beside 200 published articles Jon Bentley is the author of the famous programming books "Programming Pearls", which is a collection of 13 essays that were published in Communications of the ACM in the early 80s, and "More Programming Pearls".
Jon Bentley received in 2000 the Dr. Dobb's "Excellence in Programming Award". The award is presented to individuals who, in the spirit of innovation and cooperation, have made significant contributions to the advancement of software development.
|
|
|
Edgar Binder
|
Edgar Binder is the author of the Distance Coding algorithm (DC) and a member of the Snarl-up software team.
|
|
|
Richard Bird
|
Richard Bird is a Professor of Computing Science at the Oxford University, United Kingdom.
|
|
|
Yoram Bresler
|
Yoram Bresler works as a Professor of Electrical and Computer Engineering at the University of Illinois, United States of America.
|
|
|
Michael Burrows
|
Michael Burrows is the author of the research report, which introduces the Burrows-Wheeler Transform (BWT).
|
|
|
Anturo Campos
|
Arturo Campos is a student and programmer, interested in data compression, and has written several articles about data compression.
|
|
|
Brenton Chapin
|
Brenton Chapin is working at the University of North Texas, United States of America. His doctoral thesis was "Higher Compression from the Burrows-Wheeler Transform with New Algorithms for the List Update Problem".
|
|
|
John Cleary
|
John Cleary works at the University of Waikato, New Zealand, and has published several well known papers together with Ian Witten and Timothy Bell.
|
|
|
Sebastian Deorowicz
|
Sebastian is the author of the Weigthed Frequency Count algorithm (WFC) and is a doctoral student of the Silesian University of Technology, Poland. He just finished his dissertation.
|
|
|
Michelle Effros
|
Michelle Effros works at the Electrical Engineering department of the California Institute of Technology, United States of America. She is the director of the data compression laboratory.
|
|
|
Stefan Fabrewitz
|
Stefan Fabrewitz is a student at the University of Osnabrück, Germany. He prepared seminars in text compression and 2D-grafic concepts and is a member of the "Robotik-AG".
|
|
|
Peter Fenwick
|
Peter is a Professor at the University of Auckland, New Zealand. His primary interests are in computer architecture (including arithmetic), communications and networks, and text compression.
Beside many other papers Peter has published several papers for "symbol ranking" text compression and in the Burrows-Wheeler compression field with a very nice paper "Block Sorting Text Compression - Final Report".
|
|
|
Henning Fernau
|
Henning Fernau is working at the University of Tübingen, Germany. His research interests include Grammatical Inference, Parameterized Complexity and Formal Languages.
|
|
|
Paolo Ferragina
|
Paolo Ferragina is a Professor at the University of Pisa, Italy. His in interested in the design of algorithms and data structures for solving theoretical and applied string matching problems.
|
|
|
Robert Franceschini
|
Robert Franceschini works at the University of Central Florida, United States of America. He is interested in simulation, especially distributed and multi-resolution simulation, and computer generated forces.
|
|
|
Ole Friis
|
Ole Friis is currently studying computer science at the University of Aarhus, Denmark. Will He is an Amiga user and has a cute photo on his homepage (reminds me of Dr. Faust).
|
|
|
Markus Gärtner
|
Markus Gärtner is a member of the Communication Theory Group at the University ETH Zürich, Switzerland.
|
|
|
Robert Giegerich
|
Robert Giegerich works at the University of Bielefeld, Germany. He is interested in the fields of bioinformatics, combinatorial algorithms and term rewrite systems, programming languages and compilers.
|
|
|
Szymon Grabowski
|
Szymon is the author of a intersting RTF paper about preprocessing techniques for BWCAs.
|
|
|
Dong Ha
|
Dong Ha is a Professor at the Virginia Tech University, United States of America. His research interests are VLSI design and VLSI test.
|
|
|
David Havelin
|
David Havelin is a Electrical Engineer and lives in Ireland. He published an Artikel about BWT in image compression at the Stanford University, United States of America.
|
|
|
Yugo Isal
|
Yugo Isal is a doctoral student in the Department of Computer Science at the University of Melbourne, Australia. He is interested in searching, sorting, graphs/parallel algorithms and compression.
|
|
|
Masahiro Ishida
|
Masahiro Ishida works at the Advantest Laboratories in Miyagi, Japan.
|
|
|
Hideo Itoh
|
Hideo Itoh works at the National Institute of Advanced Industrial Science and Technology in Tokyo, Japan. His research interests include indoor locating-communicating information environment, corner reflecting and reflectivity modulating spatial optical communication module, active interposer using a beam steering VCSEL array and structural coloring technology.
|
|
|
Raja Iqbal
|
Raja Iqbal was a member of the M5 Lab, a VLSI and data compression research group at the University of Central Florida, United States of America.
|
|
|
Juha Kärkkäinen
|
Juha Kärkkäinen is a research associate in the Algorithms and Complexity Group of the Max-Planck-Institut für Informatik, Germany. His research interests include algorithms and data structures, string algorithms, algorithm engineering, data mining and computational biology.
|
|
|
Tsai-Hsing Kao
|
Tsai-Hsing Kao made his very interesting doctoral thesis "Improving Suffix-Array Construction Algorithms with Applications" at the Department of Computer Science, Gunma University Kiryu, Japan.
|
|
|
Holger Kruse
|
Holger Kruse was a member of the M5 Lab, a VLSI and data compression research group at the University of Central Florida, United States of America.
|
|
|
Sanjeev Kulkarni
|
Sanjeev Kulkarni is a Professor at Princeton University, United States of America. His research interests include statistical pattern recognition, learning, information theory, and signal/image/video processing.
|
|
|
Stefan Kurtz
|
Stefan Kurtz works at the University of Bielefeld, Germany. His research interests are algorithms and datastructures, suffix trees, functional programming and data compression.
|
|
|
Jesper Larsson
|
Jesper Larsson made his doctoral dissertation "Structures of String Matching and Data Compression" at the Lund University, Sweden.
|
|
|
Maciej Liskiewicz
|
Maciej Liskiewicz works at the University of Lübeck, Germany. His research interests are computational complexity, interactive proof systems, parallel computations, randomized algorithms and data compression.
|
|
|
Michelle Lorenz
|
Michelle Lorenz is a Master of Science student at the Computer Science Department, University of Auckland, New Zealand.
|
|
|
Spyros Magliveras
|
Spyros Magliveras is a professor of Mathematics at the Florida Atlantic University, United States of America. His main research interests are in cryptology, algebraic combinatorics, coding theory, and algorithms and their complexity, particularly those related to computational group theory.
|
|
|
Michael Maniscalco
|
Michael has focused his personal work on data compression and works as a software developer for Lexon Technologies in North Andover, United States of America.
|
|
|
Giovanni Manzini
|
Giovanni Manzini is working at the Department of informatics, University of "Piemonte Orientale", Alessandria, Italy. His main research interests are the design and mathematical analysis of algorithms, data compression and indexing data structures for large data sets.
|
|
|
Alistair Moffat
|
Alistair Moffat is working at the University of Melbourne, Australia. Together with Ian Witten and Timothy Bell he is author of the book "Managing Gigabytes".
|
|
|
Willem Monsuwe
|
Willem Monsuwe is the author of BWC, a BWCA implementation, and lives in Eindhoven, Netherlands.
|
|
|
Nitin Motgi
|
Nitin Motgi is a doctoral student at the University of Central Florida, United States of America.
|
|
|
Shin-Cheng Mu
|
Shin-Cheng Mu is a doctoral student at the University of Oxford, United Kingdom. His interests center around algebraic, relational approaches and program derivation.
|
|
|
Amar Mukherjee
|
Amar Mukherjee works as a Professor at the University of Central Florida, United States of America. His research interests include Switching Theory, Hardware Algorithms for Non-numeric Computation and VLSI.
|
|
|
Kunal Mukherjee
|
Kunal Mukherjee is a member of the M5 Research Group of the University of Central Florida, United States of America. The M5 Research Group is interested in a variety of problems related to VLSI, computational geometry and solid modeling, data compression and simulation.
|
|
|
Fei Nan
|
Fei has written a paper about the compression of protein sequences using an BWT algorithm with dictionary stage. He was a research assistant at West Virginia University, United States of America, getting his Ph.D in Computer Science in 2008 and works now as a Software Engineer at Microsoft Live Search, United States of America.
|
|
|
Mark Nelson
|
Mark is the author of the famous compression site www.datacompression.info and has published articles in the data compression field for over ten years. He is an editor of the Dr. Dobb's Journal and author of the book "The Data Compression Book". He lives in the friendly Lone Star State Texas ("All My Ex's"...).
|
|
|
Craig Nevill-Manning
|
Craig works at the Department of Computer Science of the State University of New Jersey, United States of Amrica. He published several papers about proteins.
|
|
|
Alwin Ngai
|
Alwin Ngai is a member of the Algorithms Group of the Department of Computer Science and Software Engineering at the University of Melbourne, Australia.
|
|
|
Myong-Soon Park
|
Myong-Soon Park is a Professor at the Deptartment of Computer Science and Engineering, Korea University, Korea.
|
|
|
Matt Powell
|
Matt Powell is studying Computer Science at the University of Canterbury, New Zealand. He likes academic life and drawing cartoons. As the secretary of the University Comedy Club he does all sorts of comedy, including skits, improv, stand-up and songs.
|
|
|
Kunihiko Sadakane
|
Kunihiko has developed a very fast suffix sorting algorithm with logarithmic number of passes. He wrote his dissertation about suffix sorting.
|
|
|
Peter Sanders
|
Peter Sanders works at the Max-Planck-Institut für Informatik, Germany. His research interests are algorithm engineering, id est, design, implementation and analysis of efficient algorithms; "analysis" can be both theoretical and experimental.
|
|
|
Michael Schindler
|
Michael Schindler is an independent compression consultant in Austria and the author of szip and a range coder.
|
|
|
Frank Schulz
|
Frank Schulz worked at the Department of Informatics, University of Saarland, Germany. He is interested in Searching, Markov models, information theorie, Kolmogoroff complexity.
|
|
|
Sung-Chul Shin
|
Sung-Chul Shin published an article about using the BWT for enhancements of JPEG encoding.
|
|
|
Julian Seward
|
Julian Seward is working at the Glasgow University, United Kingdom. He is a compiler-writer and the author of BZIP2, a fast BWCA implementation.
|
|
|
Yuri Shtarkov
|
Yuri Shtarkov is a researcher at the Institute for Problems of Information Transmission (IPPI), Russia. His current interests include source coding and data compression.
|
|
|
Daniel Sleator
|
Daniel Sleator is Professor at the Carnegie Mellon University, United States of America. His interts are splay trees, link parsers, music analyzers and chess.
|
|
|
Jens Stoye
|
Jens Stoye is a Professor at the University of Bielefeld, Germany. He is interested in genome informatics and algorithm.
|
|
|
Michael Tamm
|
Michael Tamm is the author of the German article "Packen wie noch nie" from the German computer magazine c't.
|
|
|
Hozumi Tanaka
|
Hozumi Tanaka is working at the Department of Computer Science at the Tokyo Institute of Technology, Japan. His research interest include natural language processing, speech understanding and machine translation.
|
|
|
Robert Tarjan
|
Robert Tarjan is Professor at the Princeton University, United States of America.
|
|
|
Stephen Tate
|
Steve Tate is working at the University of North Texas, United States of America. His research interests center in the area of computer security, with active projects in both mobile agent security and tools for secure operating system configuration and verification.
|
|
|
William Teahan
|
Bill is working at the School of Informatics in Bangor, University of Wales, United Kingdom. His research interests include text compression, information theory, compression-based language models, computational linguistics, information retrieval and text mining.
Bill is quite active in orienteering and running (I almost couldn't keep up with him, when we climbed some hills in Wales).
|
|
|
Marco Tilgner
|
Marco Tilgner works at the Deptartment of Mathematical and Computing Sciences, Tokyo Institute of Technology, Japan. He is interested in Petri nets.
|
|
|
Mark Titchener
|
Mark Titchener works at the Computer Science Department, University of Auckland, New Zealand. He is interested in deterministic information theory, measurement of entropy, data communications and coding and Data compression.
|
|
|
Karthik Visweswariah
|
Karthik Visweswariah received his PhD from Princeton University, United States of America. He works at IBM.
|
|
|
Sergio Verdú
|
Sergio Verdú is working at the Department of Electrical Engineering at the Princeton University, United States of America. His research field is information theory and multiuser communications.
|
|
|
Paul Volf
|
Paul Volf was doctoral student of Frans Willems at the University of Eindhoven, Netherlands.
|
|
|
Victor Wei
|
Victor Wei is Professor at the Chinese University of Hong Kong, Hong Kong.
|
|
|
David Wheeler
|
David Wheeler works as a Professor at the University of Cambridge, United Kingdom.
|
|
|
Ian Witten
|
Ian is working at the University of Waikato, New Zealand. Together with John Cleary and Timothy Bell he published "Modeling for Text Compression".
|
|
|
Takahiro Yamaguchi
|
Takahiro Yamaguchi was a member of the Hashimoto Laboratory, Japan.
|
|
|
Hyun-Gyoo Yook
|
Hyun-Gyoo Yook wrote a paper about using a BWCA variant in order to improve jpg-image compression.
|
|
|
Frans Willems
|
Frans Willems works at the Electrical Engineering Department of the University of Eindhoven, Netherlands. His research interests are Source coding, Channel coding and Coding for Networks.
|
|
|
Anthony Ian Wirth
|
Tony wrote several papers and a Masters thesis about direct encoding of the BWT output. He works at the Department of Computer Science at the Princeton University, United States of America.
|
|
|
Li Zhang
|
Li Zhang works at the HP Laboratories, Palo Alto, United States of America. His research interests include algorithms, computational geometry, computer security and fault tolerance.
|
|
|
Nan Zhang
|
Nan Zhang works at the University of Kaiserslautern, Germany. Her research interests include database modeling, object-oriented and relational databases and information systems.
|
|
|
Yong Zhang
|
Yong Zhang published a paper about using the BWCA for compressing DNA sequences.
|

{kind=link}